| CDH使用文档 前言:CDH在安装完毕之后,通过CM给集群添加服务组件,就可以开始各个组件的使用了,本文针对集群和各服务组件的使用作说明。 一、 创建用户目录在集群上使用CDH时,建议使用普通用户提交任务。开始使用前,需要添加对应的HDFS组件,然后在HDFS上创建自己的用户目录。创建时,需要有sudo权限。命令如下, 创建用户目录: sudo –u hdfs hadoop fs –mkdir /user/xxx (xxx代表用户名称) 给用户目录赋权限: sudo –u hdfs hadoop fs –chown –R xxx: supergroup /user/xxx (xxx代表用户名称) 创建完毕之后使用查看用户和用户组: hadoop fs –ls /user/ xxx (xxx代表用户名称) 二、 服务组件的添加对于需要使用的组件,通过CM管理界面进行添加 CDH的服务创建时候,不需要在命令行进行启动停止服务操作,启动和停止操作可以在CM端进行。 以下列出各个组件进入shell命令方法(前提该组件在CM端已经添加): 1、HDFS(需要先创建对应用户目录,参考第一步) a) 列出当前用户目录下文件及文件夹 hadoop fs –ls b) 上传数据到HDFS hadoop fs –put xxx.txt c) get数据到本地 hadoop fs –get xxx.txt d) 提交任务(以hadoop自带的examples为例) cd /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/ hadoop jar hadoop-mapreduce-examples.jar pi 10 10 2、Hive 命令行直接输入: hive
3、HBase 命令行直接输入: hbase shell
4、Spark 命令行直接输入: spark-shell
1、通过CM进行查看(mapreduce日志查看举例) 在CM端点击组件
进入状态页面
进入组件Web UI
找到自己提交的任务ID,点击history
进入任务详情页面:
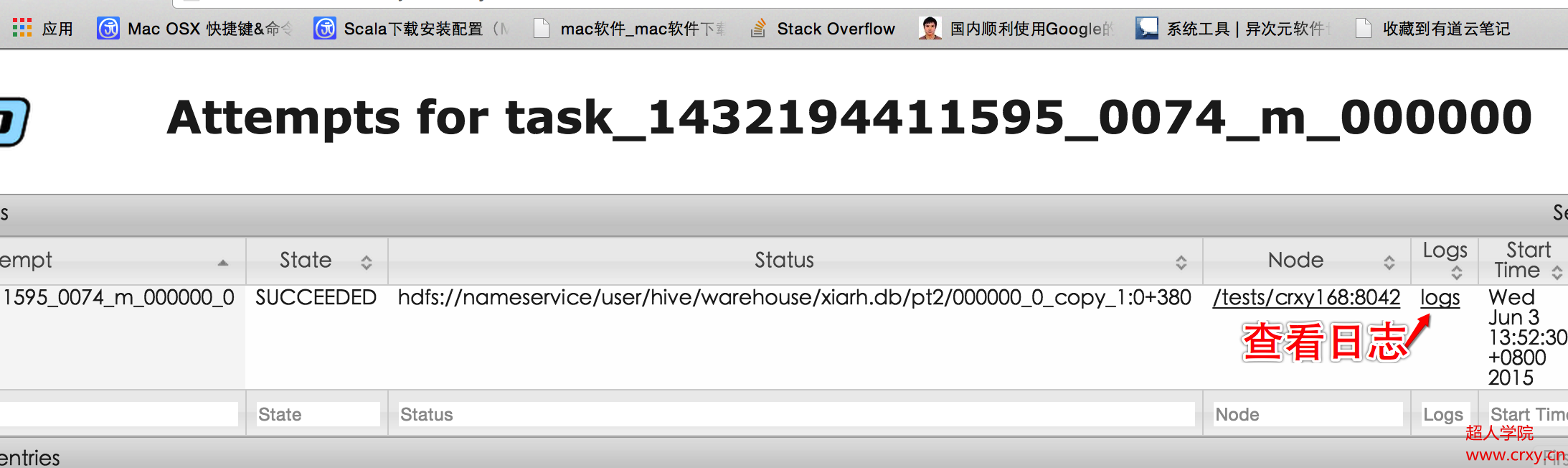
点击map进入具体的task信息
查看日志
还可以直接找到job列表
查看更详细日志
2、服务器端查看 进入到/var/log/目录 进入到对应组件目录查看相应日志(此种方式查看错误日志不是很方便,需要定位到对应job执行的机器查看日志输出) 此处为yarn的日志:
主页点击相应的组件进入状态页面:
|